
Graph Databases: 1. Introduction
I have had an interest in Graph databases for a while. In fact, a couple of years ago I presented a session on Graph Databases and Neo4j in particular at the DNN Con conference held in West Palm Beach. Graph Databases fill an important place in the array of Database options, both relational (SQL) and non-relational (NoSQL), available to us as developers. But what are Graph Databases? And what are the Graph Database implementations available to us. In this series of blog posts I will explore these topics in some detail and I invite you to join me as I learn about this important technology in the age of Social Media.
In this introductory blog I will briefly review some of the areas that I propose to explore in more detail in future posts.
What is a Graph?
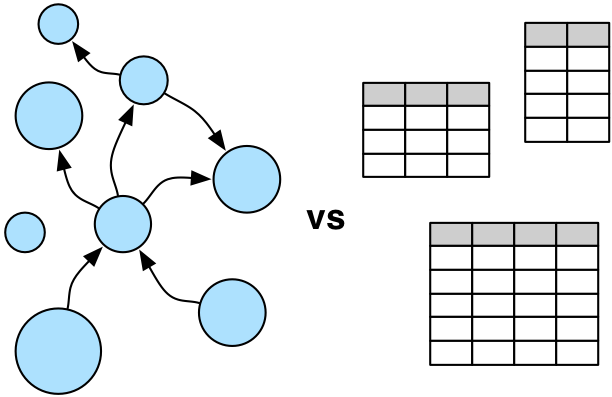 A Graph is composed of vertices and edges. Both vertices and edges can have a number of properties (key/value pairs). Vertices represent objects, such as a person, a place or an event, and in database modelling terms are very much like an entity (or table) in Relational Databases.
A Graph is composed of vertices and edges. Both vertices and edges can have a number of properties (key/value pairs). Vertices represent objects, such as a person, a place or an event, and in database modelling terms are very much like an entity (or table) in Relational Databases.
Edges denote relationships between vertices. This is where Graph Databases differ significantly from Relational Databases. The edges (or relationships) in Graph databases have properties, which add much more context than a simple foreign key relationship. Even more importantly, edges are directional.
For those of you that have studied mathematics, you will recognize the basic concepts of Graph Theory. Graph’s are not a new concept, having their genesis in the work of Leonard Euler and the Seven Bridges of Konigsberg problem, and in a future post I will spend some time reviewing this interesting story.
Modelling with Graphs
Graphs or more accurately Property Graphs are easy to visualise and without realising it, most of us already use graphs when whiteboard modelling our business domains. We draw circle’s (or sometimes squares) on the whiteboard and join them with lines. We will often annotate those lines to describe the relationship we are trying to model. See for example the simple relationship between a Product and an Order.

Because a Product can have many Orders and an Order can have many Products, when converting this conceptual model into a relational database model we will usually create three tables one for each Entity (Product and Order) and one to represent the many-to-many relationship – ProductOrders. But why should we force our conceptual “graph” into a relational database which is based on Set Theory. What if we could use a database designed to support these relationships as first class citizens. This is where Graph Databases come in.
Graph Database Implementations
![]() There are two categories of Graph Database implementations – Native and non-Native. Native Graph databases are built from the ground-up to support Graph Database concepts. A good example of a Native Graph database is Neo4j. Neo4j is one of the Graph Databases I will be reviewing in much more detail in future blog posts.
There are two categories of Graph Database implementations – Native and non-Native. Native Graph databases are built from the ground-up to support Graph Database concepts. A good example of a Native Graph database is Neo4j. Neo4j is one of the Graph Databases I will be reviewing in much more detail in future blog posts.
![]() Non-native databases use a Graph API but are implemented as an abstraction layer on top of a different storage mechanism, for example a relational database or a document database. Azure CosmosDB is a non-native database – it supports the TinkerPop Graph Database framework on top of a native Document DB. TinkerPop is a database framework and there are quite a lot of Databases that are TinkerPop-enabled – for example, in addition to Azure Cosmos DB two of the more common TinkerPop-enabled databases are Amazon Neptune and JanusGraph.
Non-native databases use a Graph API but are implemented as an abstraction layer on top of a different storage mechanism, for example a relational database or a document database. Azure CosmosDB is a non-native database – it supports the TinkerPop Graph Database framework on top of a native Document DB. TinkerPop is a database framework and there are quite a lot of Databases that are TinkerPop-enabled – for example, in addition to Azure Cosmos DB two of the more common TinkerPop-enabled databases are Amazon Neptune and JanusGraph.
Graph Query Languages
Just like relational databases share a Query Language (SQL) – there are a number of query languages supported by Graph Databases.
- Gremlin – The Gremlin query language is part of the TinkerPop specification and all TinkerPop-enabled databases support the Gremlin query language, although due to the languages popularity even other databases like Neo4j support the Gremlin query language.
- Cypher – The Cypher query language was developed for Neo4j. Although Neo4j continues to support the Gremlin query language most of its documentation uses Cypher. Quite recently there has been a push to make Cypher an open specification “Open Cypher”
- SPARQL – SPARQL is a SQL-like language that is supported by a number of Graph Databases
I will definitely be spending time in future posts on Gremlin and Cypher – the two most-commonly used languages
Conclusion
This has been a very brief overview of Graph Databases, but please plan to come along for the ride as I learn more about this fascinating technology.